Self-supervised learning for medical image classification: a systematic review and implementation guidelines
Abstract
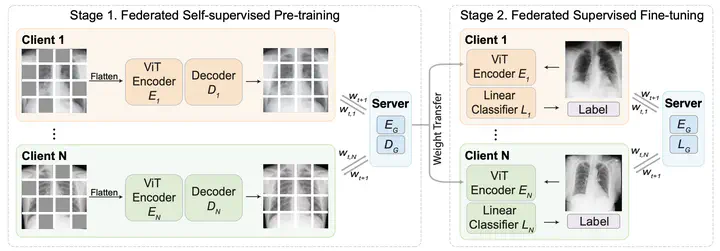
The collection and curation of large-scale medical datasets from multiple institutions is essential for training accurate deep learning models, but privacy concerns often hinder data sharing. Federated learning (FL) is a promising solution that enables privacy-preserving collaborative learning among different institutions, but it generally suffers from performance deterioration due to heterogeneous data distributions and a lack of quality labeled data. In this paper, we present a robust and label-efficient self-supervised FL framework for medical image analysis. Our method introduces a novel Transformer-based self-supervised pre-training paradigm that pre-trains models directly on decentralized target task datasets using masked image modeling, to facilitate more robust representation learning on heterogeneous data and effective knowledge transfer to downstream models. Extensive empirical results on simulated and real-world medical imaging non-IID federated datasets show that masked image modeling with Transformers significantly improves the robustness of models against various degrees of data heterogeneity. Notably, under severe data heterogeneity, our method, without relying on any additional pre-training data, achieves an improvement of 5.06%, 1.53% and 4.58% in test accuracy on retinal, dermatology and chest X-ray classification compared to the supervised baseline with ImageNet pre-training. In addition, we show that our federated self-supervised pre-training methods yield models that generalize better to out-of-distribution data and perform more effectively when fine-tuning with limited labeled data, compared to existing FL algorithms.